Contando Coches con una Raspberry Pi
En este post, voy a mostrar una pequeña parte de mi proyecto final de carrera en el que ejecuto una red neuronal convolucional en la Raspberry Pi 3 para detectar coches en una imagen. Aunque puede que no sea el mejor método, esta solución funciona bien, es divertida de ver en acción y es muy fácil de instalar siguiendo estos pasos.
Usaré una red neuronal convolucional con el sistema YOLO (You Only Look Once).
Redes Neuronales Convolucionales#
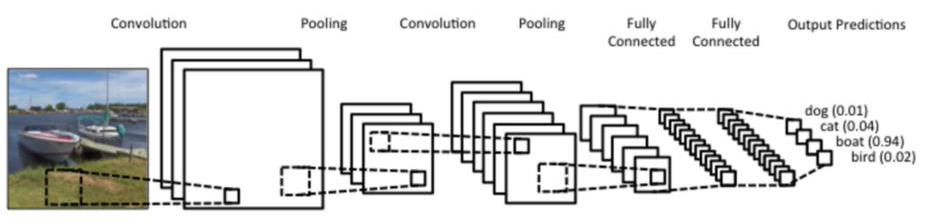
Comúnmente conocidas por su acrónimo CNN, estas redes están desarrolladas para procesar imágenes de manera eficiente. Son un tipo de red neuronal caracterizada por imitar el comportamiento del cerebro, particularmente las neuronas en la corteza visual primaria. Utilizan matrices bidimensionales, que son altamente efectivas para tareas de visión por computadora.
En el análisis de una imagen, estas redes realizan dos operaciones cruciales en sus capas ocultas conocidas como “pooling o agrupamiento” y “convolución”.
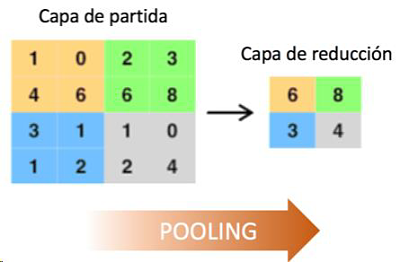
- Pooling: Consiste en reducir el tamaño de la imagen para disminuir la carga computacional en el procesamiento de la imagen por parte de la red neuronal.
- Convolución: Las capas de convolución utilizan filtros que recorren la imagen en busca de características importantes mientras reducen su tamaño. Esto se logra realizando operaciones de producto y suma entre la capa inicial y el filtro.
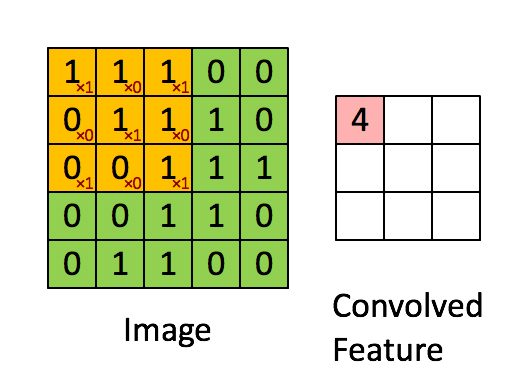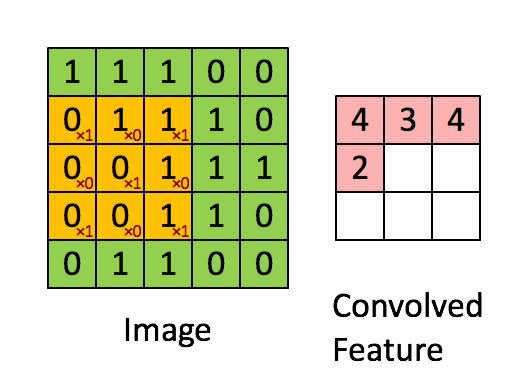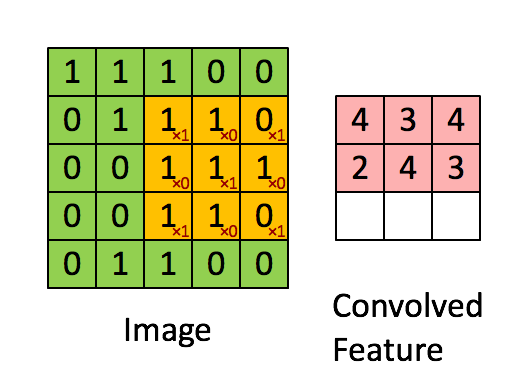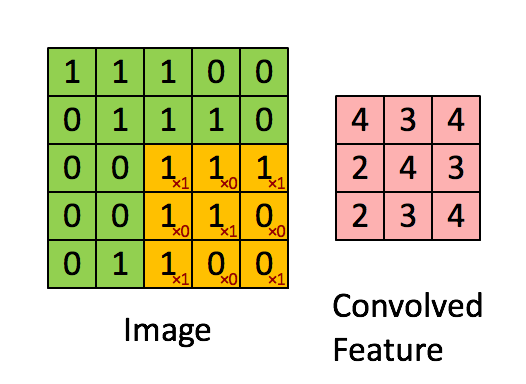
- Capa de Clasificación: Esta capa funciona como una red neuronal convencional multicapa, donde cada píxel constituye una neurona. En términos más simples, si tenemos una imagen de 10x10 en este punto, tendremos 100 neuronas.
El resultado final se ve así:
YOLO#
You Only Look Once (YOLO) es un algoritmo de detección que aprovecha el Aprendizaje Profundo y las redes neuronales convolucionales. Se diferencia de otros algoritmos porque, como su nombre indica, solo necesitas analizar la imagen una vez, a diferencia de otros que requieren múltiples pasadas. Funciona dividiendo la imagen en una cuadrícula SxS. En cada celda, N predice posibles “cajas delimitadoras”, que son rectángulos clásicos que indican el objeto detectado. Después de obtener las predicciones, se eliminan las “cajas delimitadoras” con baja certeza, es decir, con un nivel bajo de confianza.

Vamos a Ponernos a Trabajar#
Requisitos#
- Raspberry Pi 3 Modelo B+ (También funciona con el modelo B, pero la calidad de imagen puede sacrificarse.)
- Cámara USB o CSI
- Accesorios básicos de Raspberry como: fuente de alimentación de 5V, tarjeta microSD con Raspbian instalado, carcasas, etc.
No entraré en detalles sobre cómo instalar Raspbian o el software básico de Raspberry, ya que hay miles de tutoriales que lo explican. Se asume que ya tenemos un terminal listo para nuestra placa.
El primer paso es instalar Git y descargar el repositorio de la red neuronal. La red neuronal es un fork de la red neuronal Darknet.
sudo apt-get install git
git clone https://github.com/AlexeyAB/darknet
cd darknet
Una vez dentro del repositorio, necesitamos hacer algunos ajustes antes de compilar el código para que funcione en la Raspberry Pi (la Raspberry Pi tiene un microprocesador decente, pero si no se configura correctamente, la red neuronal dará un error de violación de segmento debido a la falta de memoria del microprocesador).
sudo nano Makefile
Debes modificar:
OPENMP=0 --> OPENMP=1
OpenMP es una interfaz que proporciona a la red neuronal, escrita en C, con concurrencia. Esta característica permite la ejecución de varios procesos simultáneamente en el mismo núcleo. Esto optimiza la ejecución de la red neuronal en el microprocesador de la placa.
sudo nano cfg/yolov3.cfg
Si estás utilizando una Raspberry Pi 3 Modelo B+, debes modificar:
width=608 --> width=416
height=608 --> height=416
Si estás utilizando una Raspberry Pi 3 Modelo B, debes modificar:
width=608 --> width=224
height=608 --> height=224
Con esto, reduciremos el tamaño de la imagen para la entrada de la red neuronal. Los tamaños más grandes aumentan la carga computacional, por lo que es necesario reducir un poco la resolución en el Modelo B para optimizar el rendimiento.
Ahora usamos el comando make para compilar.
make
Esto generará el ejecutable darknet. Una vez que tengamos la red neuronal lista para ejecutar, necesitamos los pesos preentrenados:
wget https://pjreddie.com/media/files/yolov3.weights
Descárgalos en el mismo directorio que darknet, donde está el ejecutable. Eso es todo. Cada ejecución toma aproximadamente dos minutos. El último paso es lanzar el ejecutable con la flag detect, añadir el archivo de configuración, el modelo preentrenado y la imagen para analizar.
./darknet detect cfg/yolov3.cfg yolov3.weights data/prueba1.jpg
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BF
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BF
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BF
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BF
4 Shortcut Layer: 1
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BF
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
8 Shortcut Layer: 5
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
...
Resultados#
La salida puede guardarse en un archivo txt y procesarse para contar el número de coches. Lo he hecho de la siguiente manera:
./darknet detect cfg/yolov3.cfg yolov3.weights /home/pi/camera/cam.jpg > /home/pi/output_NN.txt
cat /home/pi/output_NN.txt | grep car | wc -l
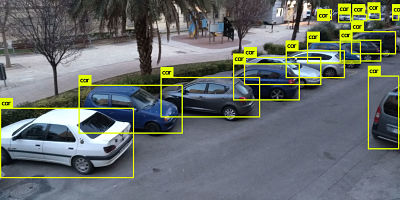
Espero que lo hayas encontrado interesante. Estoy en Twitter si quieres seguirme.
¡Adiós!